For a recent project I needed to calculate the pairwise distances of a set of observations to a set of cluster centers. In MATLAB you can use the pdist function for this. As far as I know, there is no equivalent in the R standard packages. So I looked into writing a fast implementation for R. Turns out that vectorizing makes it about 40x faster. Using Rcpp is another 5-6x faster, ending up with a 225x speed-up over the naive implementation.
At the start I wrote a naive (and very slow) implementation that look liked this:
naive_pdist <- function(A,B) {
# A: matrix with obersvation vectors
# (nrow = number of observations)
#
# B: matrix with another set of vectors
# (e.g. cluster centers)
result = matrix(ncol=nrow(B), nrow=nrow(A))
for (i in 1:nrow(A))
for (j in 1:nrow(B))
result[i,j] = sqrt(sum( (A[i,] - B[j,])^2 ))
result
}
When I realized that this is too slow, I started looking for an implementation and I found the pdist CRAN package, which is way faster:
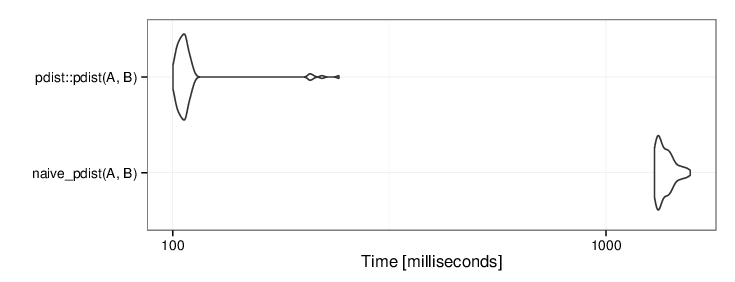
pdist::pdist is about 12x faster than the naive R implementation
The speed up made me curious about how pdist was implemented in this package. To my disappointment it is the same naive method only written in C (and using float, not double precision) — no vectorization and no tricks involved. So I was pretty sure there was room for improvement.
In search for tricks on computing the pairwise distance a blog post from Alex Smola turned up. He suggest to “use the second binomial formula to decompose the distance into norms of vectors in A and B and an inner product between them”. Translated into R code this solution looks like this:
vectorized_pdist <- function(A,B)
an = apply(A, 1, function(rvec) crossprod(rvec,rvec))
bn = apply(B, 1, function(rvec) crossprod(rvec,rvec))
m = nrow(A)
n = nrow(B)
tmp = matrix(rep(an, n), nrow=m)
tmp = tmp + matrix(rep(bn, m), nrow=m, byrow=TRUE)
sqrt( tmp - 2 * tcrossprod(A,B) )
}

Vectorized R pdist is 3x faster than naive C pdist
Now that I knew how to implement pdist with a couple of simple operations, I wanted to know how much faster a C (or C++) implementation would be. Thanks to the excellent Rcpp and RcppArmadillo package, it is easy to translate the above R code into C++:
#include <RcppArmadillo.h>
// [[Rcpp::depends(RcppArmadillo)]]
using namespace Rcpp;
// [[Rcpp::export]]
NumericMatrix fastPdist2(NumericMatrix Ar, NumericMatrix Br) {
int m = Ar.nrow(),
n = Br.nrow(),
k = Ar.ncol();
arma::mat A = arma::mat(Ar.begin(), m, k, false);
arma::mat B = arma::mat(Br.begin(), n, k, false);
arma::colvec An = sum(square(A),1);
arma::colvec Bn = sum(square(B),1);
arma::mat C = -2 * (A * B.t());
C.each_col() += An;
C.each_row() += Bn.t();
return wrap(sqrt(C));
}
This C++ implementation turns out to be another 6x faster than the vectorized R implementation:
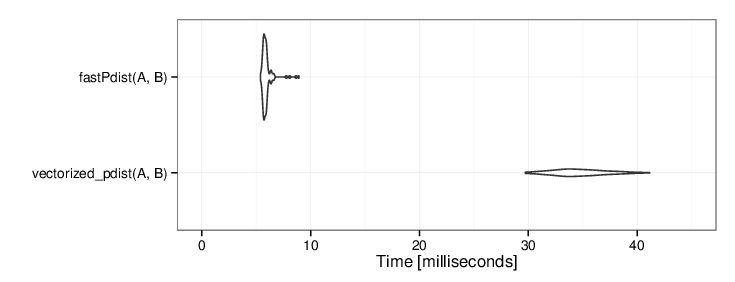
RcppArmadillo achieves another 6x speed-up over the R implementaion
All implementations compared
The time measurements for all implementations:
Unit: milliseconds
expr min lq median uq max neval
vectorized_pdist(A, B) 26.667005 30.299216 32.945532 34.548596 134.8368 100
fastPdist(A, B) 5.357734 5.581193 5.693534 5.798465 109.9736 100
naive_pdist(A, B) 1259.290444 1280.897937 1290.150653 1320.467180 1425.3864 100
pdist::pdist(A, B) 98.825835 101.955146 103.719962 105.843313 205.7123 100
and the speed up among all implementations:
| vectorized C++ | vectorized R | naive C | naive R | |
|---|---|---|---|---|
| vectorized C++ | 1.00 | 5.79 | 18.23 | 226.74 |
| vectorized R | 0.17 | 1. 00 | 3.15 | 39.15 |
| naive C | 0.05 | 0.32 | 1.00 | 12.44 |
| naive R | 0.00 | 0.03 | 0.08 | 1.00 |
Conclusion
In my example the (naive) C implementation only acheived a 12x speed up, while the improved R implementation was about 40x faster. These findings agree with what is preached in various blog posts and guides about R: first try to vectorize code, then try to find a faster method (algorithm), and only as last step consider using a faster language.
Tags: optimization, pairwise distance, pdist, R, speed up
`pdist` takes into account NAs. I wonder if your fast implementation allows this feature.
You can speed up the R vectorized_pdist even more by not using apply, because apply will do many function calls, which are slow in R. For example:
Instead of
an = apply(A, 1, function(rvec) crossprod(rvec,rvec))
bn = apply(B, 1, function(rvec) crossprod(rvec,rvec))
just do
an = rowSums(A^2)
bn = rowSums(B^2)
great post, thanks.
Just a small type: in the second vectorized example you’re missing a ‘{‘ after ‘function(A,B)’.